Notre article intitulé « The PARES Database : Information Extraction over Historical Parish Records » a été publié dans l’International Journal of Document Analysis and Recognition (IJDAR) en mai 2025. Ce travail a été réalisé au cours de l’avant-projet, dans le cadre du programme France Relance.
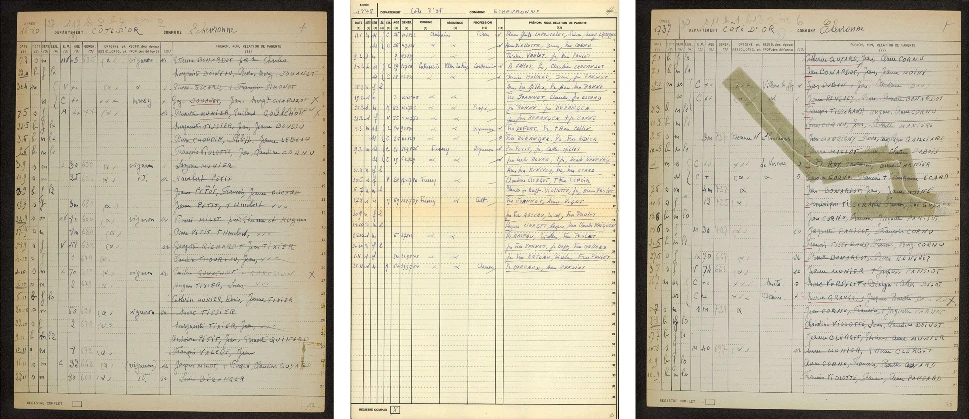
Résumé : Les registres de recensement historiques contiennent des informations précieuses pour la recherche généalogique et les études démographiques. En raison du grand volume de ces documents, il est essentiel de développer des méthodes permettant l’extraction automatique des données qu’ils renferment. Dans cette étude, nous présentons un nouveau corpus composé de 535 tableaux de recensement historiques issus des archives françaises. En complément de ce jeu de données, nous évaluons trois méthodes de base pour l’extraction d’informations. Les deux premières suivent une approche séquentielle classique, consistant à détecter d’abord les lignes du tableau avant d’en extraire le contenu. La troisième méthode repose sur un modèle de type « end-to-end », capable d’extraire directement les informations à partir des images de tableaux, sans étape préalable de détection des lignes. Nos résultats montrent que les trois approches sont efficaces pour relever les défis liés à l’extraction d’informations à partir de ce type de documents.
Mots clés : Dataset, Documents historiques, Extraction d’informations, Documents manuscrits structurés.
Citation: Andrés, J., Wall, C., Tarride, S., Coustaty, M., Toselli, A., Vidal, E. The PARES Database: Information Extraction over Historical Parish Records. IJDAR (2025). https://doi.org/10.1007/s10032-025-00531-z
Lien vers l’article : https://link.springer.com/article/10.1007/s10032-025-00531-z (open-access)